
Spis treści
- Business Continuity Plan, czyli plan ciągłości działania
- Disaster Recovery Plan (DRP) – plan odzyskiwania po awarii
- RPO i RTO – kluczowe wartości w planie awaryjnym
- Co powinien zawierać Disaster Recovery Plan?
- 1. Spis wykorzystywanych urządzeń i programów
- 2. Ocena krytyczności danych obszarów
- 3. Oszacowanie ryzyka i wpływu na biznes
- 4. Ustalenie celów planu odtwarzania po awarii
- 5. Stworzenie kompleksowego dokumentu
- 6. Umieszczenie DRP w bezpiecznym miejscu
- 7. Testowanie planu i wprowadzanie ulepszeń
- 8. Cykliczne szkolenia personelu i aktualizacje dokumentu
- Kopia zapasowa a Disaster Recovery Center
- Disaster Recovery Plan w Google Cloud
- Architektura chmury Google – podział na zony i regiony
- Wzorce odzyskiwania po awarii dostępne w Google Cloud Platform
- Przykłady scenariuszy Disaster Recovery Plan dla aplikacji
- Scenariusze Disaster Recovery Plan dla danych
- Kopia zapasowa do chmury oraz odzyskiwanie danych aplikacji działającej na on-premise
- Kopia zapasowa danych w chmurze dla aplikacji działającej na GCP
- Kopia zapasowa bazy danych w chmurze Google
- Zarządzane chmurowe bazy danych w GCP
- Kopia zapasowa dla danych danych aplikacji działającej w innej chmurze publicznej
Działalność wielu biznesów polega dzisiaj na dostępności systemów informatycznych. Wiele firm, dotychczas funkcjonujących jedynie w sferze offline, przeszło przez ekspresowy proces cyfrowej transformacji w wyniku pandemii. Przejście do online’u z jednej strony przekłada się na większą płynność i elastyczność, z drugiej – na niemal całkowitą zależność od technologii.

A awarie się zdarzają. Czy to w wyniku niedopatrzenia po stronie dostawcy usług, błędu pracownika, ataku hakerskiego, czy katastrofy naturalnej. Niezależnie od przyczyny, incydent może przełożyć się na ogromne straty. Część przedsiębiorstw jest skazana na zamknięcie działalności, ponieważ nie są w stanie odtworzyć dotychczasowego trybu pracy, utraconej aplikacji czy danych lub koszt ich odzyskania jest zbyt duży.
Według badań uśredniony koszt minutowej przerwy w funkcjonowaniu systemu dużych przedsiębiorstw waha się od 5600 $ do 9000 $ (Gartner, Ponemon Institute). W przypadku małych i średnich przedsiębiorstw jest to od 137 $ do 427 $ (Carbonite). 13-minutowa przerwa w funkcjonowaniu serwisu Amazon.com w 2015 roku kosztowała firmę ponad 2,5 miliona dolarów. A są to dane dotyczące jedynie przerwy w dostawie usług – nie utraty systemu czy informacji i kosztów ich odtworzenia.
Każda kolejna minuta niedostępności systemu przekłada się na coraz większe straty. Dlatego istotne jest zadbanie o bezpieczeństwo danych i kluczowych elementów aplikacji, przygotowanie planu awaryjnego i przeszkolenie personelu, by w obliczu incydentu jak najszybciej przywrócić stabilne działanie serwisu.
Business Continuity Plan, czyli plan ciągłości działania
Business Continuity Plan pozwala sprawnie zarządzać sytuacjami kryzysowymi w kluczowych obszarach przedsiębiorstwa oraz minimalizować skutki incydentu. DCP powinien przewidywać takie sytuacje jak:
- katastrofa naturalna (trzęsienie ziemi, powódź),
- awaria budynku (zalanie, pożar, katastrofa budownicza),
- wypadek komunikacyjny (np. w przypadku firm spedycyjnych),
- kradzież czy zniszczenie fizycznych dokumentów,
- kradzież sprzętu firmowego,
- włamanie do systemu informatycznego.
W planie ciągłości należy wskazać obszary kluczowe dla funkcjonowania przedsiębiorstwa – przykładowo, zachowanie fizycznych dokumentów, utrzymanie budynku, w którym znajduje się siedziba firmy czy archiwum, zapewnienie bezpieczeństwa pracowników w obliczu katastrofy.
Do każdego z kluczowych obszarów powinien być rozpisany proces reakcji, obejmujący wytyczne komunikacyjne (np. kogo i w jakiej kolejności poinformować o incydencie) oraz informacje o kolejnych krokach. Instrukcje powinny być przedstawione w jak najbardziej zrozumiały sposób, a personel przeszkolony na wypadek wystąpienia sytuacji kryzysowej. Dokument i jego kopie powinny być zabezpieczone i znajdować się w kilku lokalizacjach – by w obliczu awarii nie utracić również instrukcji obsługi takiego kryzysu.
W przypadku przedsiębiorstw, których głównym filarem działalności jest technologia, obowiązkową pozycją w Business Continuity Plan jest Disaster Recovery Plan, czyli plan odzyskiwania systemów i danych po awarii.
Disaster Recovery Plan (DRP) – plan odzyskiwania po awarii
Disaster Recovery Plan to dokument zawierający opis procedur, jakie należy podjąć w razie awarii w obszarze IT – incydentu we własnym centrum danych, awarii po stronie dostawcy usług, problemów w funkcjonowaniu aplikacji, wystąpieniu krytycznego błędu w systemie czy przerwy w dostępności cyfrowych narzędzi pracy.
Celem planu odzyskiwania po awarii jest jak najszybsze uruchomienie stabilnej aplikacji (całej lub kluczowych jej obszarów) oraz przywrócenie dostępu do danych i możliwości dalszego ich przetwarzania. Szybka i zaplanowana reakcja ma skrócić czas niedostępności systemu i ograniczyć jego skutki.
Dla przykładu – załóżmy, że posiadamy sieć sklepów stacjonarnych oraz serwis e-commerce. Powinniśmy zabezpieczyć się na wypadek takich sytuacji jak:
- krytyczny błąd w wersji produkcyjnej sklepu internetowego,
- wyłączenie systemu ERP,
- atak hakerski, kradzież lub wyciek danych,
- awaria centrum danych i idąca za nią niedostępność serwisu czy systemu ERP,
- awaria serwera pocztowego,
- wyłączenie systemu obsługi klienta (również z winy dostawcy usług),
- awaria terminala lub systemu POS.
Jeśli któreś z tych sytuacji są kluczowe dla dalszego funkcjonowania przedsiębiorstwa, Disaster Recovery Plan powinien je uwzględniać.
Jednym z powodów dlaczego warto współpracować z Partnerem Google takim jak FOTC jest fakt, że nasi inżynierowie są w stanie pomóc Ci stworzyć DRP i przygotowąć firmę na niespodziewane okoliczności.
RPO i RTO – kluczowe wartości w planie awaryjnym
W dokumencie Disaster Recovery Plan powinny znaleźć się dwa wskaźniki – Recovery Point Objective i Recovery Time Objective. Obie wartości są wartościami czasowymi i przedstawia się je najczęściej w minutach lub godzinach.

Recovery Point Objective (RPO) to wartość pokazująca, jaki okres czasu obejmuje ostatnia przeprowadzona kopia zapasowa czy transfer danych do centrum Disaster Recovery. Jeśli w aplikacji co kilka minut wprowadzane są istotne zmiany, RPO powinno wynosić właśnie kilka minut. Jeśli aktualizacje następują rzadziej lub mają mniejszą wagę, wartość RPO może być równa kilku godzinom.
Recovery Time Objective (RTO) to miara, która wskazuje, jaki jest maksymalny czas na przywrócenie funkcjonowania po awarii – czyli ile maksymalnie czasu system może być wyłączony. RTO często jest składową Service Level Agreement (SLA), więc określenie wartości jest kluczowe m.in. do spełnienia warunków zawartej z klientem umowy.
Im niższą wartość mają Recovery Point Objective i Recovery Time Objective (im szybciej zależy nam na przywróceniu najnowszej wersji systemu), tym wyszły będzie koszt odzyskania po awarii.

Co powinien zawierać Disaster Recovery Plan?
To, jakie obszary należy pokryć i jakie działania podjąć w obliczu kryzysu, jest kwestią indywidualną każdego przedsiębiorstwa i każdego systemu.
Jest jednak kilka uniwersalnych kroków, które należy wykonać, przygotowując plan odzyskiwania po awarii. Oto one:
1. Spis wykorzystywanych urządzeń i programów
Pierwszym krokiem jest swego rodzaju “inwentaryzacja IT” – czyli przygotowanie listy wykorzystywanych elektronicznych i cyfrowych produktów, od których zależy funkcjonowanie przedsiębiorstwa, a które mogą zawieść.
Na liście powinny znaleźć się m.in.:
- używane narzędzia zewnętrznych dostawców (np. serwer poczty, aplikacje biznesowe, system ticketowy),
- fizyczny sprzęt (np. nośniki elektroniczne, komputery czy serwery należące do firmy),
- wynajmowane zasoby wirtualne (np. od hostingodawcy, w chmurze prywatnej lub publicznej),
- kluczowe dokumenty cyfrowe i miejsce ich przechowania,
- elementy aplikacji czy bazy danych ze wskazaniem ich lokalizacji.
2. Ocena krytyczności danych obszarów
Następnym krokiem jest ocena poziomu krytyczności danych elementów. Należy wskazać, które obszary działalności ucierpią w sytuacji braku dostępu do danych informacji czy danych narzędzi i jaki wpływ będzie to miało na ciągłość funkcjonowania biznesu.
3. Oszacowanie ryzyka i wpływu na biznes
Należy ocenić, jakie są potencjalne zagrożenia dla danych obszarów oraz jakie konsekwencje ze sobą niosą. Pod uwagę należy wziąć niewielkie incydenty (jak błąd strony skutkujący kilkuminutowym przestojem), jak też najczarniejsze scenariusze (np. całkowite zniszczenie centrum danych wraz z plikami aplikacji).
Dobrze jest ocenić finansową wartość danych elementów, posiłkując się informacjami o przychodzie, jaki generuje dany obszar. W sieci dostępne są propozycje wzorów na obliczenie kosztu nawet minuty przestoju systemu.
Określenie potencjalnych incydentów i ich skutków pozwala wskazać realne cele i wskaźniki w następnych krokach opracowania planu.
4. Ustalenie celów planu odtwarzania po awarii
Mając listę elementów o najwyższym priorytecie, należy wskazać RTO i RPO dla poszczególnych obszarów. Jeśli dany element jest krytyczny, czas przywrócenia jego możliwie najnowszej wersji powinien być jak najkrótszy. Pod cele należy przygotować procesy i strategią przywracania po awarii. Przykładowo, jeśli firma świadczy wysokie SLA, powinna zadbać o jak najszybszą i nasprawniejszą reakcję z Disaster Recovery Center.
5. Stworzenie kompleksowego dokumentu
Wyżej wymienione informacje – spis elementów aplikacji, używanych narzędzi, wykorzystywanego sprzętu wraz z priorytetami – powinny zostać spisane w przejrzysty i zrozumiały sposób do jednego dokumentu. DRP powinien być instrukcją dla osób, które zauważają incydent i ma umożliwić im szybką i zorganizowaną reakcję.
Disaster Recovery Plan powinien zawierać m.in.:
- spis używanych narzędzi cyfrowych i/lub tworzonych własnych produktów,
- spis wykorzystywanych sprzętów fizycznych i zasobów wirtualnych ze wskazaniem dostawcy,
- listę pracowników odpowiedzialnych za dany obszar,
- wskazanie danych kontaktowych do osób, które trzeba powiadomić o incydencie,
- harmonogram działań, jakie należy wykonać w sytuacji danego incydentu, obejmujący m.in. opis incydentu, określenie strat, poinformowanie użytkowników o przerwie w dostawie usług, wskazanie niezbędnych kroków do przywrócenia działania systemu (np. ścieżkę do kopii zapasowej czy instrukcję uruchomienia Disaster Recovery Center),
- opis działań niezbędnych do podjęcia po uruchomieniu systemu, np. test obciążenia, analiza zaistniałej sytuacji czy przygotowanie opisu zdarzenia, tzw. postmortem.
6. Umieszczenie DRP w bezpiecznym miejscu
Dokument oraz jego kopie powinny znajdować się kilku lokalizacjach, łatwo dostępnych dla pracowników. Z pewnością Disaster Recovery Plan nie można zamieścić w tym samym miejscu co innych kluczowych plików i danych, ponieważ w sytuacji incydentu, dostęp do niego również zostanie utracony.
Przykładowo, jeśli korzystasz z własnego centrum danych, dokument DRP możesz przechowywać na innym, oddalonym geograficznie serwerze lub w chmurze.
7. Testowanie planu i wprowadzanie ulepszeń
Następnym krokiem jest przeprowadzenie testu planu i wszystkich procedur. Pozwoli to zweryfikować obrane wskaźniki, wskazać obszary potencjalnego zagrożenia i ulepszyć plan.
Ten krok jest niezwykle istotny – często dopiero w praktyce okazuje się, że niektóre punkty wymagają znacznej modyfikacji. Testy wskażą też, w jakich obszarach należy położyć mocny nacisk na szkolenie personelu.
8. Cykliczne szkolenia personelu i aktualizacje dokumentu
Należy przygotować i przeprowadzić szkolenie personelu. Szkolenia powinny być cyklicznie odświeżane, podobnie jak sam Disaster Recovery Plan.
FOTC to wsparcie specjalistów, zniżki na usługi GCP
Kopia zapasowa a Disaster Recovery Center
Kopia zapasowa (backup) polega na skopiowaniu istotnych elementów aplikacji – np. plików z kodem źródłowym, baz danych, dokumentów elektronicznych – i zamieszczenia ich w innej lokalizacji. Takie rozwiązanie nie zawsze jest wystarczające. Jeśli utracimy dostęp do infrastruktury, uruchomienie kopii zapasowej w innym środowisku może zająć od kilkudziesięciu minut do nawet kilku godzin czy dni. Nie wszystkie dane też mogą zostać przywrócone – załóżmy, że kopia zapasowa jest wykonywana codziennie o północy, a strona zostaje wyłączona po godzinie 23.00. Tracimy dane, które były zbierane przez całą poprzednią dobę.
Natomiast Disaster Recovery Center (DRC) to działające 24/7, zapasowe centrum danych. To oddalona geograficznie zapasowa infrastruktura firmy, która łączy się z główną infrastrukturą i przechowuje kopię całego systemu i baz danych. W sytuacji awarii głównego centrum, ruch można przepiąć do centrum zapasowego – nawet w tak krótkim czasie, że użytkownicy aplikacji nie zauważą jakiegokolwiek przestoju.
Z Disaster Recovery Center można korzystać w trzech modelach:
- Disaster Recovery Center on-premise jako własne zapasowe centrum danych. Powinno być na tyle oddalone geograficznie, by przetrwało potencjalną katastrofę, a jednocześnie na tyle dobrze skomunikowane, by czas przesyłu danych był jak najmniejszy. Takie rozwiązanie łączy się z wysokim kosztem, ponieważ potrzebne jest drugie tyle zasobów (koszty budynku i zabezpieczeń, sprzęt fizyczny, opłacenie specjalistów), co przy utrzymaniu głównego centrum danych;
- Disaster Recovery Center off-premise, czyli zewnętrzne centrum danych, należące do dostawcy usług. Usługodawca musi zapewnić wysokie standardy w obszarze bezpieczeństwa fizycznego maszyn i sieci, stabilności łącza, prędkości przesyłu czy dostępności. Koszt “wynajęcia” DRC off-premise jest często niższy niż budowa własnego DRC on-premise;
- Disaster Recovery as a Service (DRaaS) – centrum zapasowe w chmurze. Usługa DRaaS polega na kopiowaniu całego środowiska i przechowywaniu w chmurze dostawcy usług. Awaryjne uruchomienie systemu jest stosunkowo łatwe i szybkie, ponieważ infrastruktura jest obsługiwana z konsoli w przeglądarce, a RTO może wynosić nawet kilka minut.
Disaster Recovery Plan w Google Cloud
Google Cloud oferuje dostępność usług na poziomie 99,95-99,99%. Posiada własną sieć światłowodową łączącą ponad 70 centrów danych na całym świecie. Niektóre lokalizacje, w celu zachowania większej dostępności w obliczu awarii czy katastrof, są połączone w regiony. Region to zespół przynajmniej trzech stref, gdzie dwie służą właśnie jako Disaster Recovery Center i utrzymują funkcjonowanie aplikacji w sytuacji ewentualnego zniszczenia jednego centrum.
Infrastruktura Google wspiera szybkie odzyskiwanie po awarii; to między innymi dzięki:
- globalnej sieci składającej się z setek centrów danych i dziesiątek tysięcy łączących je kabli światłowodowych,
- redundancji dzięki posiadaniu wielu punktów PoP (point of presence) oraz automatycznemu kopiowaniu danych pomiędzy urządzeniami w różnych lokalizacjach,
- skalowalności, która w ciągu ułamków sekund umożliwia przyjęcie kilkunastokrotnie zwiększonego obciążenia; w przypadku wielu usług skalowanie odbywa się automatycznie,
- bezpieczeństwu rozwijanemu od 15 lat przez zespół setek specjalistów ds. cybersecurity i infosec,
- zgodności z regulacjami i wymaganiami prawnymi, m.in. z certyfikacją ISO 27001, SOC 2/3 czy PCI DSS 3.0.
Obok wysokiej dostępności i wydajności, jaką zapewnia Google Cloud, dużą zaletą jest wsparcie certyfikowanych specjalistów. Lokalni Partnerzy Google Cloud są w stanie wesprzeć organizację w opracowaniu Disaster Recovery Plan i przygotowaniu stabilnego Disaster Recovery Center w chmurze Google.
Architektura chmury Google – podział na zony i regiony
Infrastruktura chmury publicznej została stworzona w taki sposób, by domyślnie gwarantować wysoką dostępność usług, również w obliczu katastrofy obejmującej centra danych dostawcy.
Na chmurę Google obecnie (kwiecień 2021) składa się 76 zon połączonych w 25 regionów. Czym są zony, a czym regiony?
Zona to strefa dostępności, którą wskazuje użytkownik podczas konfiguracji usług cloud computing (np. maszyn wirtualnych w usłudze Compute Engine). Zona nie jest równoznaczna z centrum danych – pomiędzy zoną a klastrem fizycznych maszyn w serwerowni Google’a znajduje się warstwa abstrakcji. Zona może składać się z jednego lub więcej takich klastrów, ale nie jest na stałe przypisana do konkretnych urządzeń w konkretnym centrum danych.
Natomiast region to połączona grupa minimum trzech zon. Zony znajdujące się w jednym regionie posiadają połączenia sieciowe o dużej przepustowości i małych opóźnieniach (poniżej 5 milisekund).
Użytkownik Google Cloud może wskazać lokalizację dla danych usługi jako:
- zonal – w obszarze jednej zony,
- regional – w obszarze kilku zon w regionie,
- multi-regional – pomiędzy dwoma lub więcej regionami.
Wdrażając aplikację w modelu zonal jestesmy narażeni na skutki ewentualnej awarii, na przykład w wyniku katastrofy naturalnej. Wdrożenie w modelu regional zapewnia większą dostępność dzięki przesyłaniu informacji i równoważeniu obciążenia pomiędzy zasobami w zonach. Pozwala to mininalizować przestoje i zachować dostępność nawet w sytuacji poważnego incydentu w fizycznym centrum danych. Model multi-region zapewnia globalną dostępność – np. pomiędzy kontynentami – i chroni przed skutkami awarii całego regionu (jak, przykładowo, zdarzyło w 2017 roku w chmurze AWS).

Ponieważ dane nie są przechowywane na konkretnych maszynach, a nieprzerwanie dzielone, replikowane i dystrybuowane pomiędzy maszynami w różnych lokalizacjach, awaria fizycznego centrum danych nie ma dużego wpływu na dostępność aplikacji w chmurze. W przypadku wystąpienia awarii w data center zasoby i dostępy są automatycznie przenoszone do innego centrum danych, by użytkownicy chmury Google nie odczuli żadnych przestojów w pracy aplikacji. W centrach danych znajdują się też awaryjne generatory, które zasilają budynki i maszyny w przypadku przerwy w dostawie prądu. W każdym centrum 24/7 pracują administratorzy i specjaliści security, którzy dbają o zachowanie ciągłości działania zarówno usług i aplikacji Google, jak też zachowania dostępności zasobów klientów.
Wzorce odzyskiwania po awarii dostępne w Google Cloud Platform
W Google Cloud Platform można zbudować scenariusz odzyskiwania po awarii według trzech wzorców:
- cold – przewidujący przerwę w pracy systemu do momentu odzyskania danych,
- warm – przewidujący krótszą przerwę w działaniu, tylko do momentu uruchomienia zastępczych zasobów,
- hot – zapewniający nieprzerwaną pracę systemu i, nierzadko, automatyczną naprawę czy automatyczne odzyskiwanie.
W wideo z serii “Get cooking in Cloud” zamieszczonym kilka akapitów wyżej, Priyanka Vergadia opisuje te trzy modele na przykładzie przygotowania ciasta na przyjęcie, które organizuje wieczorem. Mikser, którego używa, zaczyna wydawać niepokojące dźwięki, sugerujące, że maszyna może lada chwila się zepsuć;
- w modelu cold Priyanka może przerwać przygotowania i wezwać serwis do naprawy urządzenia; takie działanie jednak mocno spowolni jej prace i nie pozwoli przygotować ciasta na imprezę,
- w modelu warm może na jakiś czas przerwać przygotowania i samodzielnie naprawić mikser, korzystając z instrukcji; straci tym samym trochę czasu, ale zapewne uda się jej wyrobić ze wszystkim przed wieczornym przyjęciem,
- w modelu hot zmniejsza obroty miksera do bezpiecznego poziomu i kończy przygotowania, a usterką zajmuje się później, po przyjęciu.
Przykłady scenariuszy Disaster Recovery Plan dla aplikacji
Kiedy środowisko produkcyjne znajduje się na on-premise
W modelu cold w projekcie DR w chmurze Google posiadamy jak najmniej zasobów – jedynie tyle, by uruchomić scenariusz odzyskiwania w razie awarii. Jako bloki Disaster Recovery Plan możemy wskazać:
- Cloud DNS,
- Cloud Interconnect,
- Self-managed VPN,
- Cloud Storage,
- Compute Engine,
- Cloud Load Balancing,
- Deployment Manager.
Poniższy diagram ilustruje przykładową architekturę odzyskiwania po awarii:
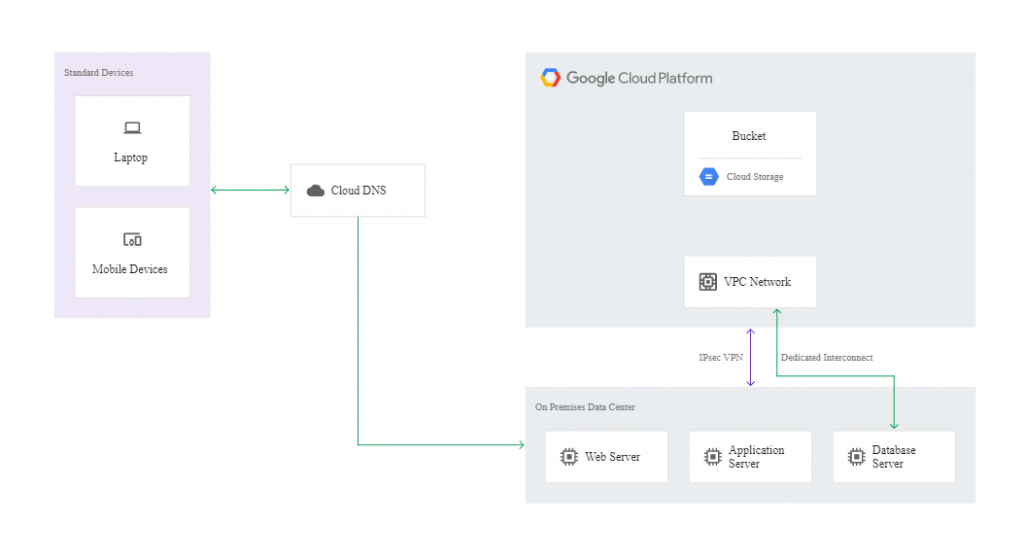
W sytuacji wystąpienia incydentu można przywrócić działanie aplikacji w chmurze. W tym celu należy uruchomić proces odzyskiwania w środowisku stworzonym przez Deployment Manager. Kiedy instancje w zapasowym środowisku będą gotowe by przyjąć ruch, należy zmienić DNS tak, by wskazywał web server Google Cloud. Działanie można odwrócić, gdy główne środowisko zostanie naprawione.
Niżej znajduje się diagram prezentujący działanie zapasowego środowiska w modelu cold:
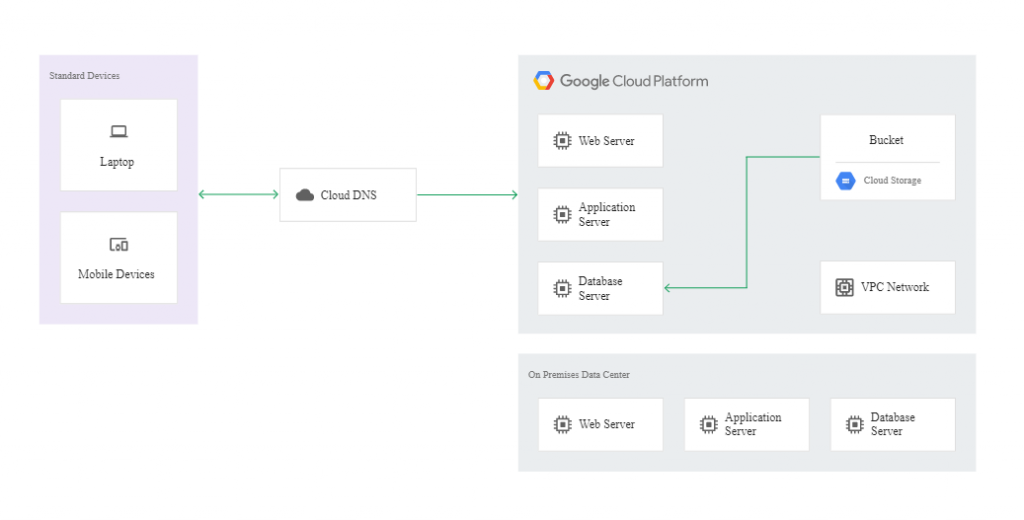
W modelu warm zapasowa instancja musi działać przez cały czas, by przyjmować repliki transakcji za pomocą asynchronicznych lub pół-synchronicznych technik replikacji. Jako zapasowe centrum można wskazać maszynę o najniższych parametrach, umożliwiających uruchomienie kopii systemu i baz danych. Ponieważ instancja będzie działała nieprzerwanie przez długi okres czasu, automatycznie naliczą się zniżki Sustained Use Discounts (oszczędność do 30% kosztów usługi miesięcznie).
W tym scenariuszu główną rolę odgrywa snapshot maszyny wirtualnej. Na bloki DR składają się usługi:
- Cloud DNS,
- Cloud Interconnect,
- Self-managed VPN,
- Compute Engine,
- Deployment Manager.
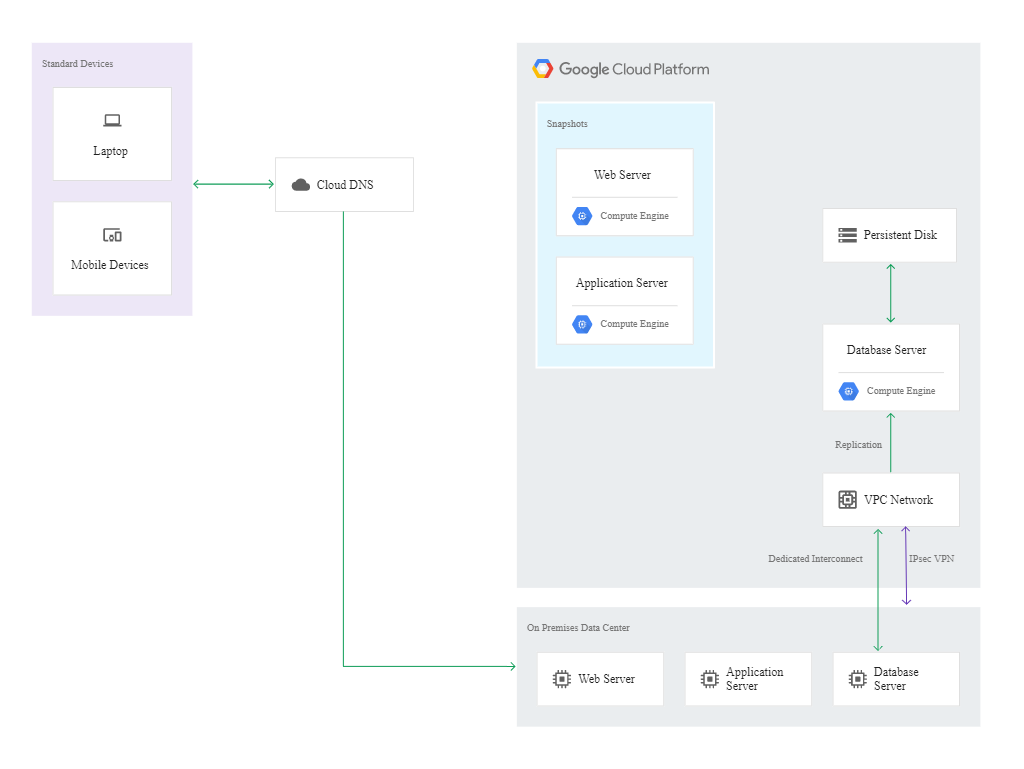
Ciągłość działania infrastruktury jest automatycznie monitorowana, a ustawione alerty uruchamianą proces odzyskiwania w odpowiedzi na awarię. W razie konieczności awaryjnego przełączania ruchu na maszyny Compute Engine, administrator powinien skonfigurować system bazy danych w Google Cloud, by mógł on przyjmować ruch z wersji produkcyjnej aplikacji. Następnie uruchamiane są web server i application server.
Poniższy diagram przedstawia konfigurację po przełączeniu awaryjnym do Google Cloud:
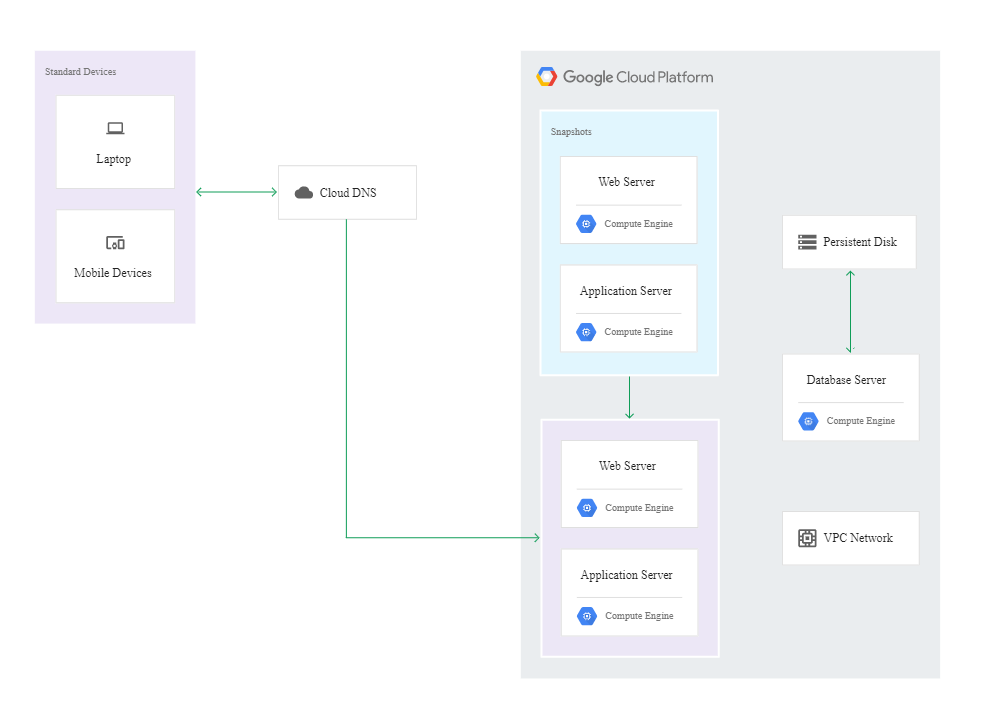
W modelu hot i infrastruktura on-premise, i infrastruktura w chmurze działają w trybie produkcyjnym i obsługują ruch z aplikacji. W tym scenariuszu konieczność ingerencji administratora jest sprowadzona do minimum, ponieważ reakcja na awarię i odzyskiwanie są wykonywane automatycznie.
Na bloki DR składają się następujące usługi chmurowe:
- Cloud Interconnect,
- Cloud VPN,
- Compute Engine,
- Managed instance groups,
- Cloud Monitoring,
- Cloud Load Balancing.
Diagram poniżej prezentuje przykładową architekturę w modelu hot:
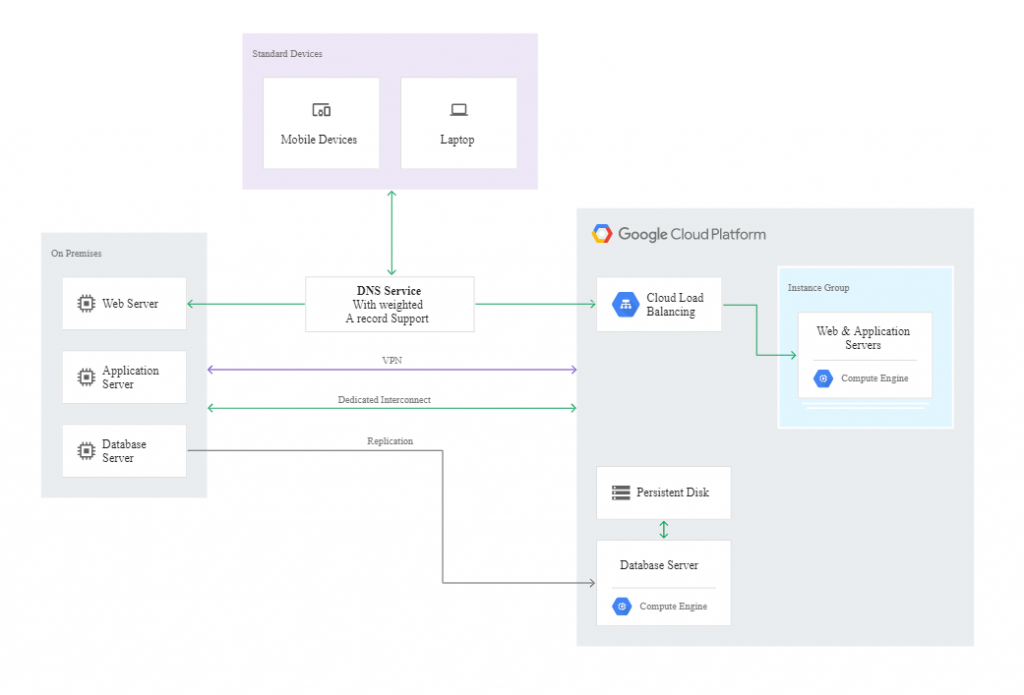
W tym przypadku nie ma procesu przełączania awaryjnego pomiędzy głównym, a zapasowym centrum. Może się jednak zdarzyć, że konieczne będzie wprowadzenie kilku zmian w konfiguracji:
- jeśli DNS nie przekierowuje automatycznie ruchu na podstawie złego wyniku healtchecka, należy ręcznie zmienić konfigurację routingu DNS, by ruch był kierowany do działającego systemu,
- jeśli system bazodanowy nie promuje automatycznie repliki tylko do odczytu jako repliki podstawowej z możliwością zapisu w przypadku awarii, należy zmienić ustawienia tak, by ta replika była promowana.
Po ponownym uruchomieniu jednej z dwóch infrastruktur konieczne będzie zsynchronizowanie baz danych między środowiskami. Ponieważ oba obsługują ruch produkcyjny, nie będzie konieczne wskazywanie, która baza danych jest główna. Po synchronizacji można ponownie zezwolić na dystrybucję ruchu w ustawieniach DNS.
Kiedy środowisko produkcyjne znajduje się w Google Cloud Platform
W modelu cold dla środowiska produkcyjnego znajdującego się w Google Cloud Platform jako centrum zapasowe potrzebna jest jedna instancja. Najczęściej taka instancja jest elementem grupy MIG używanej jako backend dla wewnętrznego Load Balancingu.
W tym scenariuszu na bloki DR składają się usługi:
- Compute Engine,
- Google Cloud Internal Load Balancing.
Niżej znajduje się diagram prezentujący przykładową architekturę. Nie uwzględnia połączenia z klientem, ponieważ ten najczęściej nie łączy się bezpośrednio z serwerem aplikacji (zwykle między klientem a serwerem znajduje się proxy lub aplikacja webowa).
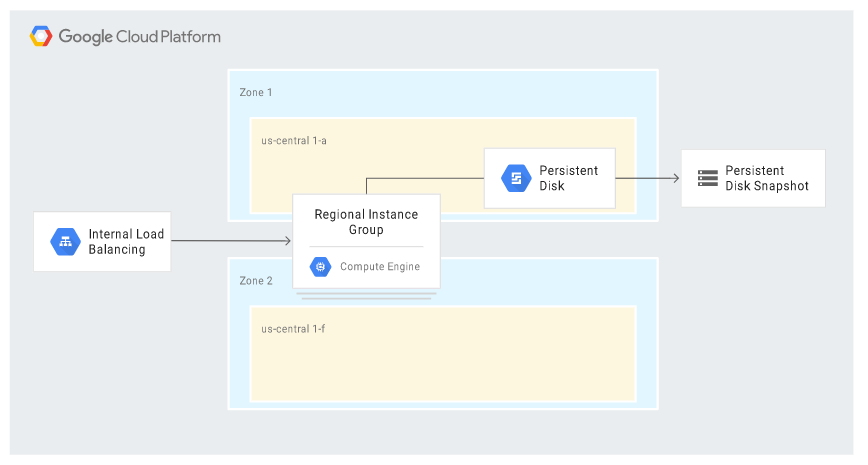
Scenariusz uwzględnia niektóre funkcje chmury Google zapewniające dostępność (HA). W obliczu awarii akcje są wykonywane automatycznie; nowy serwer otrzymuje identyczny adres IP oraz ten sam zestaw konfiguracji, co główna instancja. W przypadku awarii zony, MIG w modelu regional uruchamia zastępczą instancję w innej, funkcjonującej zonie, na którą wgrywany jest najnowszy snapshot. Diagram poniżej prezentuje architekturę w sytuacji wystąpienia awarii:
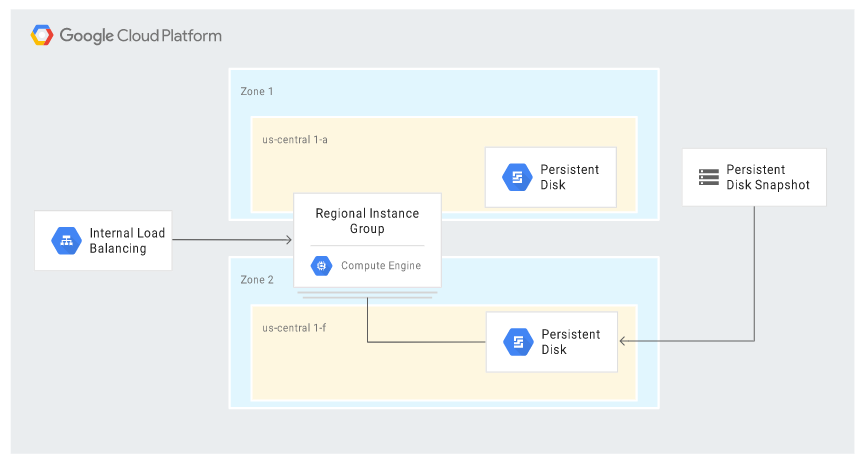
W modelu warm, gdy główna aplikacja działa w usłudze Compute Engine, a awarii ulega instancja GCE, można awaryjnie uruchomić statyczną wersję strony używając do tego Cloud Storage.
Jako komponenty odzyskiwania (DR building blocks) służą:
- Compute Engine,
- Cloud Storage,
- Cloud Load Balancing,
- Cloud DNS.
Niżej znajduje się diagram przykładowej architektury:
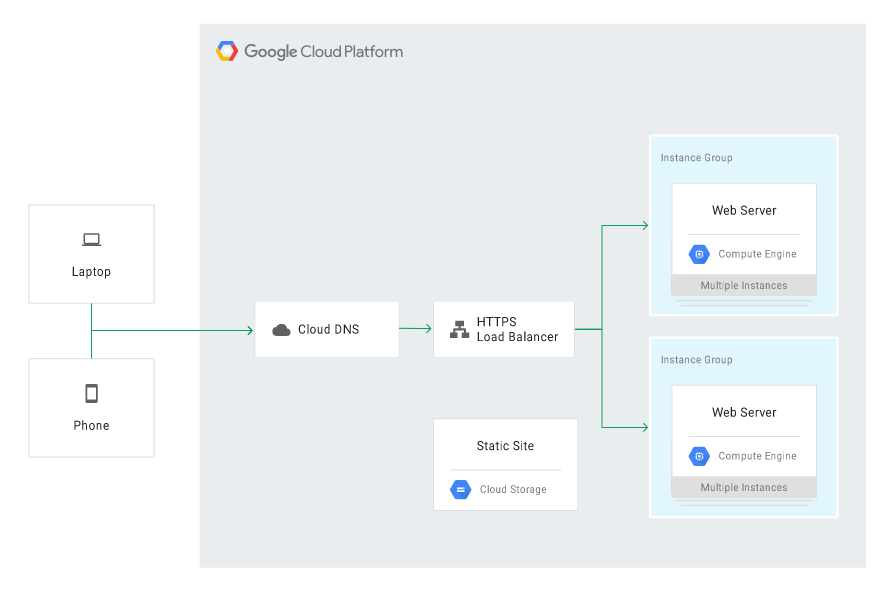
Cloud DNS powinien być skonfigurowany tak, by kierować ruch na główną aplikację w usłudze Compute Engine, a witrynę w Cloud Storage trzymać nieaktywną, ale gotową na wypadek awarii. W sytuacji awarii GCE, Cloud DNS należy skonfigurować tak, by kierował ruch na witrynę statyczną w Cloud Storage:
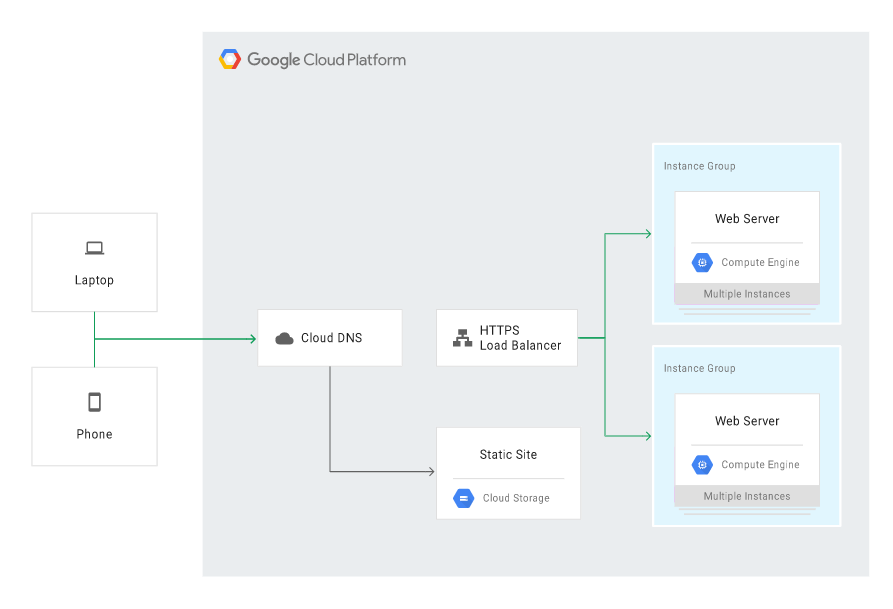
By zbudować scenariusz w modelu hot, można wykorzystać usługi i mechanizmy Google zapewniające wysoką dostępność HA, m.in.:
- Managed Instance Groups w usłudze Compute Engine, w modelu regional lub multi-regional,
- healthchecki i automatyczne naprawianie w grupie instancji
- Load Balancing,
- zarządzaną bazę danych w chmurze, np. Cloud SQL.
Scenariusze w modelu hot zakładają, że administrator nie musi podejmować żadnych kroków w celu przywracania, ponieważ wszystkie akcje wykonywane są automatycznie.
Niżej znajduje się przykładowy scenariusz składający się z building blocks:
- Compute Engine,
- Cloud Load Balancing,
- Cloud SQL.
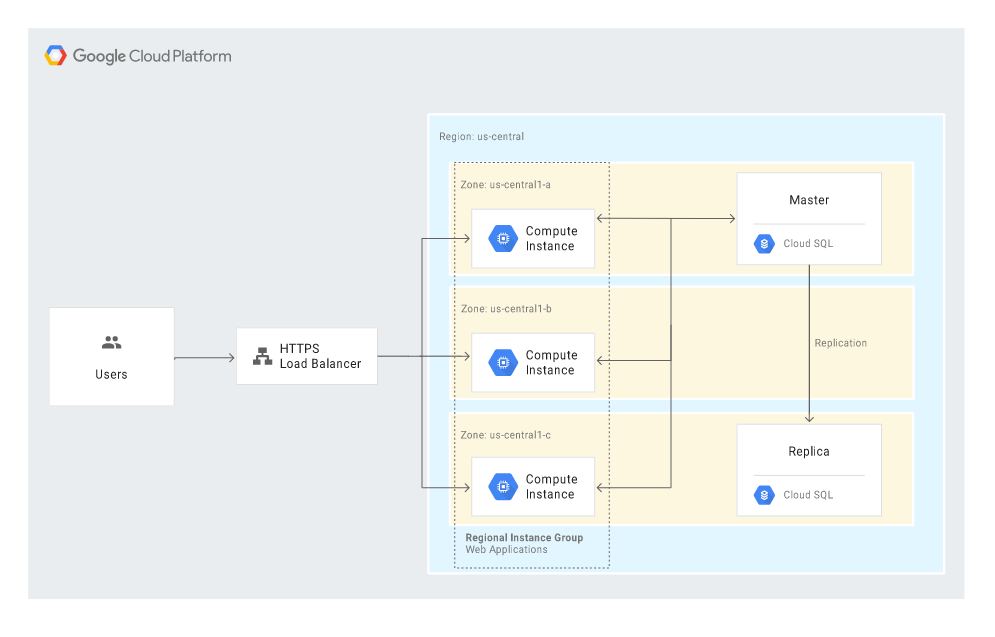
Scenariusze Disaster Recovery Plan dla danych
Disaster Recovery Plan powinien wskazywać, w jaki sposób zachować dane w obliczu awarii. Przez “dane” rozumiemy bazy danych, zapisy logów, dzienniki transakcji, jak też konfigurację bazy danych i dopasowanie do wersji produkcyjnej, umożliwiające szybkie i efektywne uruchomienie.
Kopia zapasowa do chmury oraz odzyskiwanie danych aplikacji działającej na on-premise
Jeśli aplikacja funkcjonuje lokalnie – na własnych serwerach czy w chmurze prywatnej – można wykorzystać Google Cloud Platform jako zapasowe centrum danych na kilka sposobów:
- kopia zapasowa do Google Cloud Storage poprzez automatyczne uruchamianie skryptu (operacja możliwa do wdrożenia z poziomu wiersza poleceń gsutil lub przez biblioteki dostępne dla najpopularniejszych języków programowania),
- automatyczna kopia zapasowa do Google Cloud Storage z użyciem Transfer service for on-premises data,
- automatyczna kopia zapasowa z użyciem rozwiązania third-party, np. NAS lub SAN.
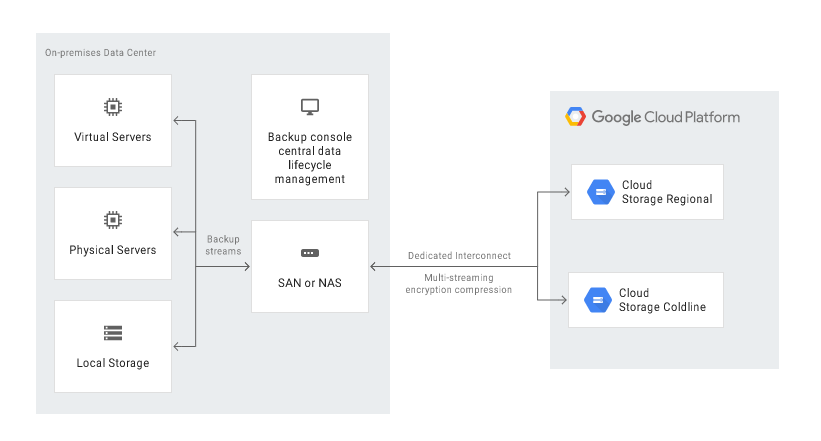
Dane można odzyskać na dwa sposoby:
- wykonując kopię zapasową i odzyskiwanie z serwera recovery w Google Cloud (tutaj znajduje się instrukcja),
- replikując dane na serwer w trybie standby w Google Cloud (instrukcja).
Kopia zapasowa danych w chmurze dla aplikacji działającej na GCP
W Google Cloud możemy robić cykliczny eksport danych do usługi Google Cloud Storage. Eksportować możemy dane z usługi maszyn wirtualnych Compute Engine, ale też z innych usług, na przykład usług baz danych (np. Cloud SQL).
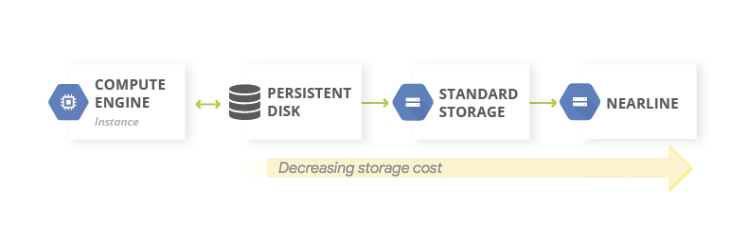
Żeby zapewnić optymalizację kosztów na ścieżce przechowywania kopii zapasowej, możemy korzystać z klas przechowywania GCS – zmieniać je manualnie lub ustawić automatyczną zmianę klasy w ramach Object Lifecycle Management.

Kopia zapasowa bazy danych w chmurze Google
Jeśli korzystamy z Compute Engine, możemy wykonywać snapshoty, które działają podobnie jak backup (a nawet lepiej, bo proces odtwarzania jest kwestią jednego kliknięcia w konsoli).
Niżej znajduje się scenariusz automatycznego odzyskiwania po awarii, którego głównymi blokami są usługi Compute Engine (z Managed instance groups – MIGs) oraz Cloud Load Balancing:
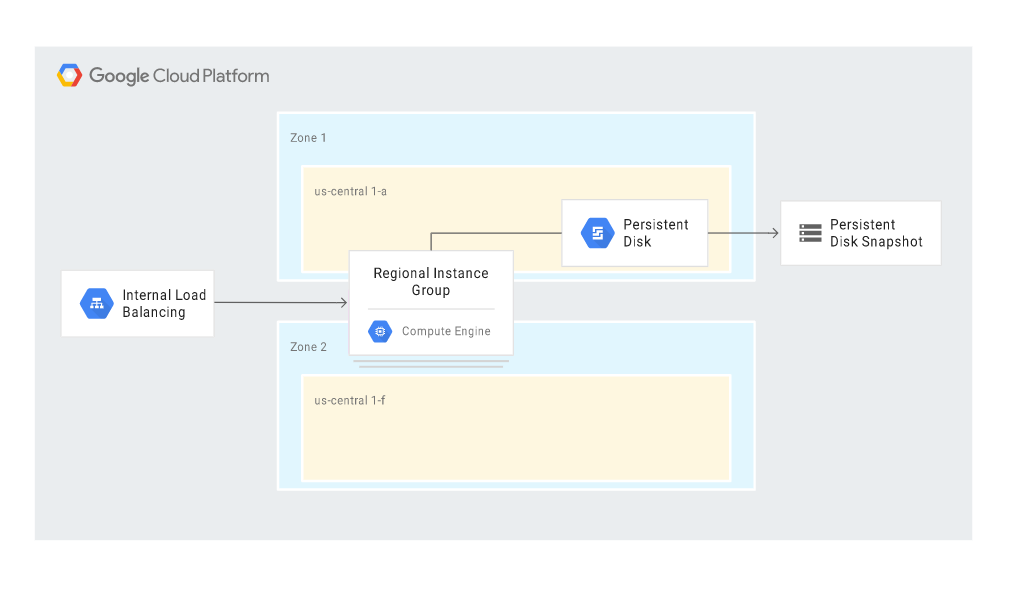
Scenariusz wykorzystuje niektóre funkcjonalności HA (high availability) dostępne w Google Cloud i właściwie ogranicza do minimum konieczność ingerencji administratora w proces odzyskiwania. Kroki wykonywane są automatycznie w odpowiedzi na powstanie awarii.
W sytuacji awarii instancji w MIG, tworzona jest instancja zastępcza. Nowa instancja zachowuje ten sam adres IP dzięki funkcjonalności wewnętrznego load balancera, a instance template i custom i custom image zapewniają identyczną konfigurację. Na zastępczej instancji przywracany jest stan z najnowszego snapshotu oraz automatycznie przywracany jest dziennik logów.
Podobnie w przypadku odzyskiwania bazy danych. W takim scenariuszu tworzona jest zastępcza instancja serwera bazy danych, dołączany jest persistent disk, na którym znajdują się kopie zapasowe i zapis logów oraz automatycznie ustawiane są te same reguły (poziomy dostępu i role, firewall), które były na głównym serwerze.
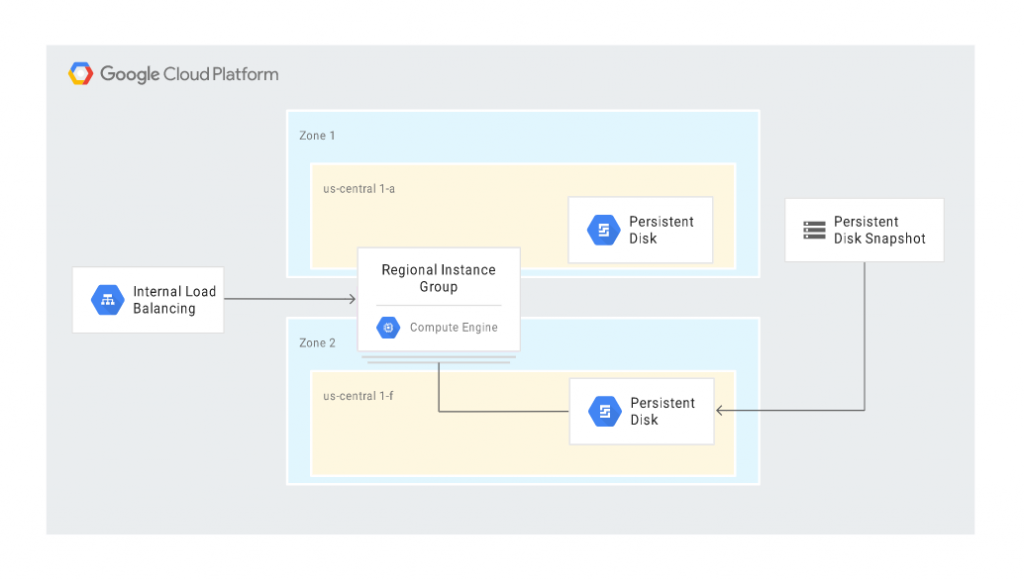
Na diagramie poniżej przedstawiono scenariusz DR, w którym persistent disk został przywrócony w innej zone ze snapshota:
Zarządzane chmurowe bazy danych w GCP
Żeby usprawnić wykonywanie kopii zapasowej oraz odzyskiwanie po awarii można korzystać z mechanizmów HA dostępnych w usługach baz danych w chmurze Google zaprojektowanych z myślą o skalowaniu, m.in.:
- Cloud Bigtable – wysoce wydajna baza NoSQL,
- BigQuery – usługa hurtowni danych,
- Firestore – baza danych dla aplikacji mobilnych i webowych (dostępna na platformie Firebase),
- Cloud SQL – usługa bazy danych MySQL, PostgreSQL i SQL Server,
- Cloud Spanner – relacyjna baza danych o wysokiej dostępności (99,999%).
Kopia zapasowa dla danych danych aplikacji działającej w innej chmurze publicznej
W portfolio usług Google Cloud Platform znajduje się Storage Transfer Service – usługa relatywnie łatwego transferu zasobów z on-premise czy innych chmur publicznych do magazynu Google Cloud Storage. Usługa jest kompatybilna m.in. z Amazon S3 czy Azure Blob Storage.
Storage Transfer Service pozwala zaplanować i ustawić cykliczną synchronizację danych lub transfer z innego rozwiązania do chmury Google. W przypadku Amazon S3 wystarczy podać klucz dostępu, wskazać bucket oraz opcjonalnie filtry, a następnie skopiować obiekty z S3 do Cloud Storage.
Zobacz też:
- 20 powodów, by wybrać infrastrukturę chmurową GCP
- Przenoszenie WordPressa na serwer w chmurze. Przykład manualnej migracji do Google Cloud Platform
- Cloud Storage od Google Cloud – magazyn w chmurze GCP
FOTC to wsparcie specjalistów, zniżki na usługi GCP